|
Haiwen (Haven) Feng Hi, I'm Haven! I'm a 4th year PhD student at Max Planck Institute for Intelligent Systems (MPI-IS), advised by Michael J. Black.
Before my PhD, I received M.Sc. and B.Sc. degrees in Physics at the University of Tübingen. For my master's, I researched disentangled representation learning with Wieland Brendel and Matthias Bethge at Tübingen AI Center. During my bachelor's, I worked on 3D face reconstruction with Timo Bolkart and Michael J. Black at MPI-IS. |

|
|
|
|
|
|
Research
I'm interested in machine learning, computer vision, and computer graphics, particularly in how to recreate the visual world. My research explores the essential structures in visual data—from 3D geometry, group symmetries to symbolic abstractions, physical priors, and beyond—to develop steerable and scalable learning systems.
|

|
GenLit: Reformulating Single-Image Relighting as Video Generation
Shrisha Bharadwaj*, Haiwen Feng*, Giorgio Becherini, Victoria Fernandez Abrevaya, Michael J. Black (*Equal contribution, listed alphabetically) SIGGRAPH Asia, 2025 project page / arXiv Could we reformulate single image near-field relighting as a video generation task? By leveraging video diffusion models and a small synthetic dataset, we achieve realistic relighting effects with cast shadows on real images without explicit 3D. Our work reveals the potential of foundation models in understanding physical properties and performing graphics tasks. |
|
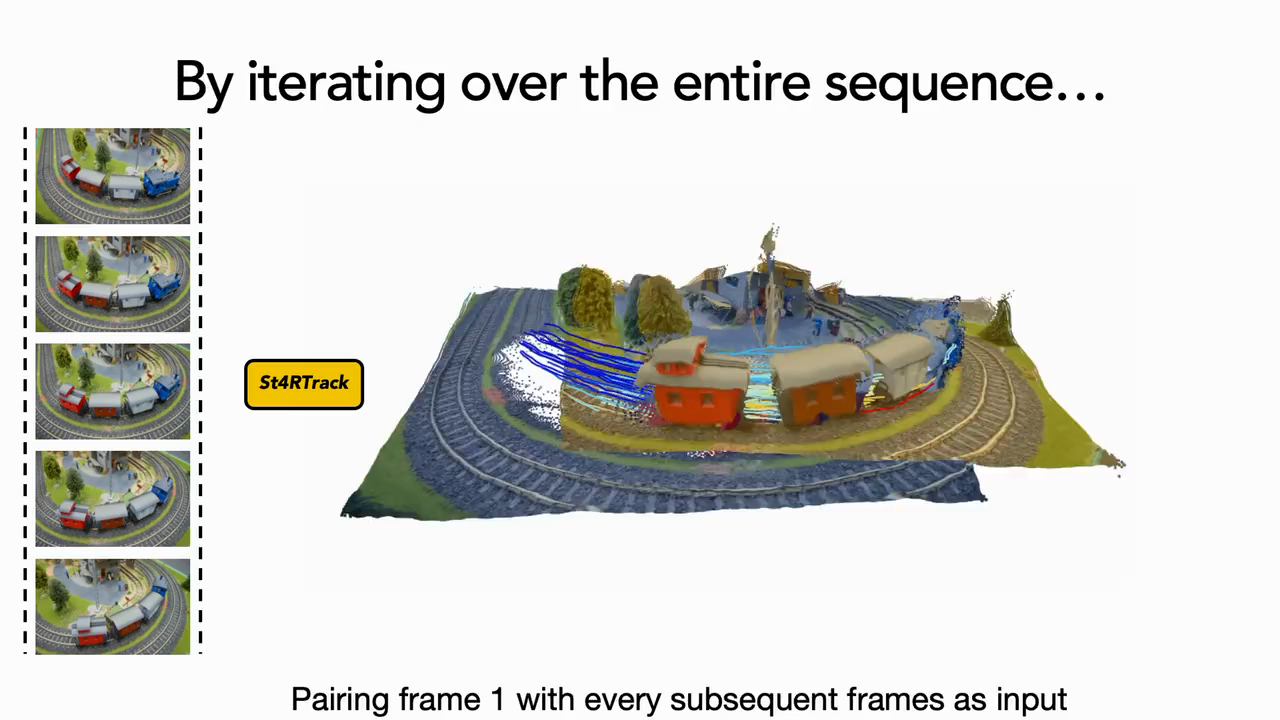
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Haiwen Feng*, Junyi Zhang*, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, Angjoo Kanazawa (*Equal contribution, listed alphabetically) ICCV, 2025 project page / arXiv What is the minimal representation required to model both geometry and correspondence of the 4D world? Could it be done in a unified framework? It turns out to be remarkably simple! We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate from monocular video, embedding the 4D understanding into the transformer-based backbone. |

|
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Boqian Li, Haiwen Fengᐩ, Zeyu Cai, Michael J. Black, Yuliang Xiu (ᐩProject lead) ICCV, 2025 (Highlight Presentation) project page / arXiv ArtEq was great, but how do we fit a body to a 3D clothed human point cloud? We propose ETCH, a novel pipeline leveraging local SE(3) equivariance to map cloth-to-body surfaces, encoding tightness as displacement vectors. ETCH simplifies fitting into a marker fitting task, outperforming state-of-the-art methods in accuracy and generalization across challenging scenarios. |

|
InterDyn: Controllable Interactive Dynamics with Video Diffusion Models
Rick Akkerman*, Haiwen Feng*ᐩ, Michael J. Black, Dimitrios Tzionas, Victoria Fernandez Abrevaya (*Equal contribution ᐩProject lead) CVPR, 2025 project page / arXiv Can we generate physical interactions without physics simulation? We leverage video foundation models as implicit physics simulators. Given an initial frame and a control signal of a driving object, InterDyn generates plausible, temporally consistent videos of complex object interactions. Our work demonstrates the potential of using video generative models to understand and predict real-world physical dynamics. |
|
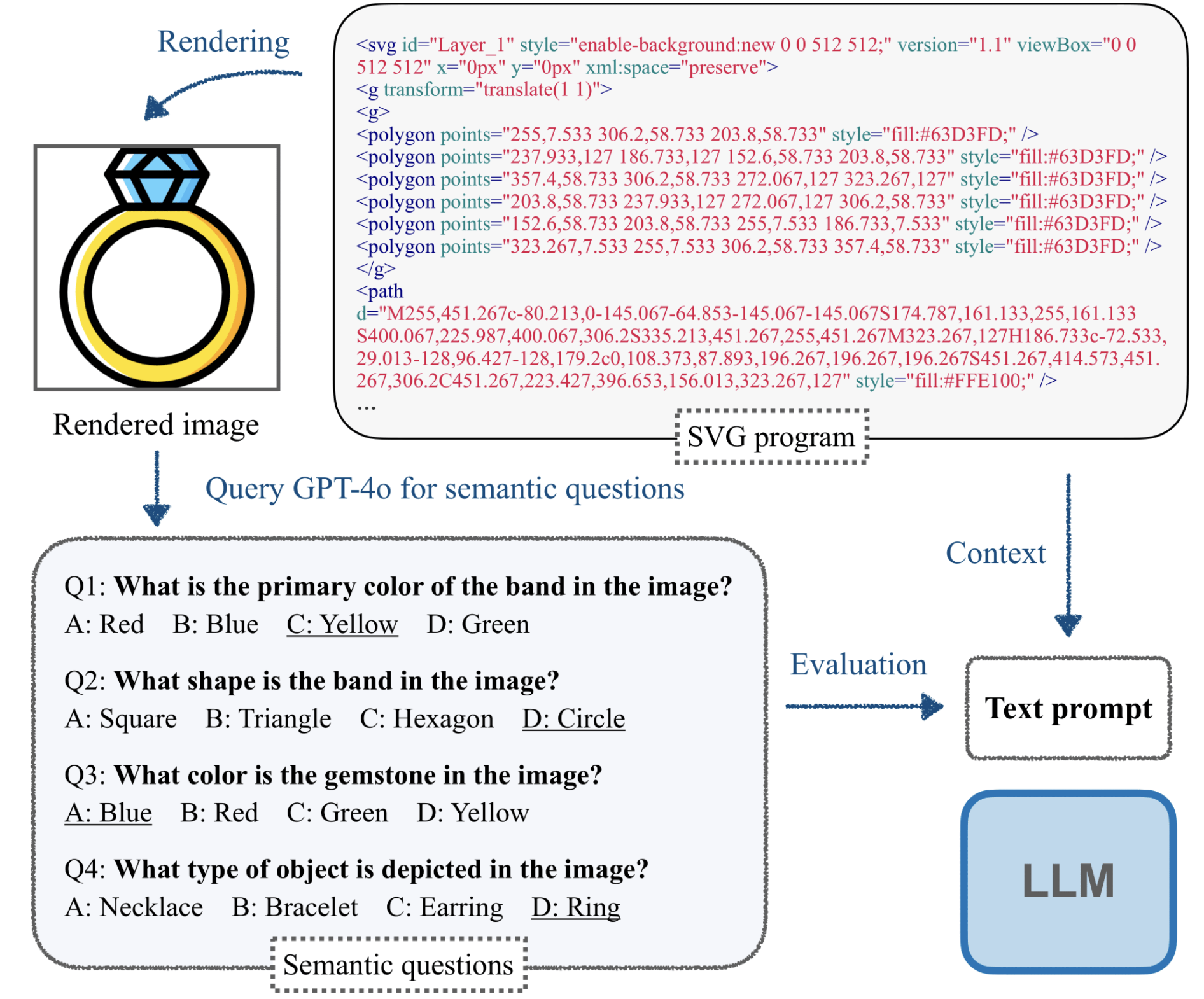
SGP-Bench: Can Large Language Models Understand Symbolic Graphics Programs?
Zeju Qiu*, Weiyang Liu*, Haiwen Feng*, Zhen Liu, Tim Z. Xiao, Katherine M. Collins, Joshua B. Tenenbaum, Adrian Weller, Michael J. Black, Bernhard Schölkopf (*Joint first author) ICLR, 2025 (Spotlight Presentation) project page / arXiv / code We questioned whether LLMs can "imagine" how the corresponding graphics content would look without visually seeing it! This task requires both low-level skills (e.g., counting objects, identifying colors) and high-level reasoning (e.g., interpreting affordances, understanding semantics). Our benchmark effectively differentiates models by their reasoning abilities, with performance consistently aligning with the scaling law! |
|
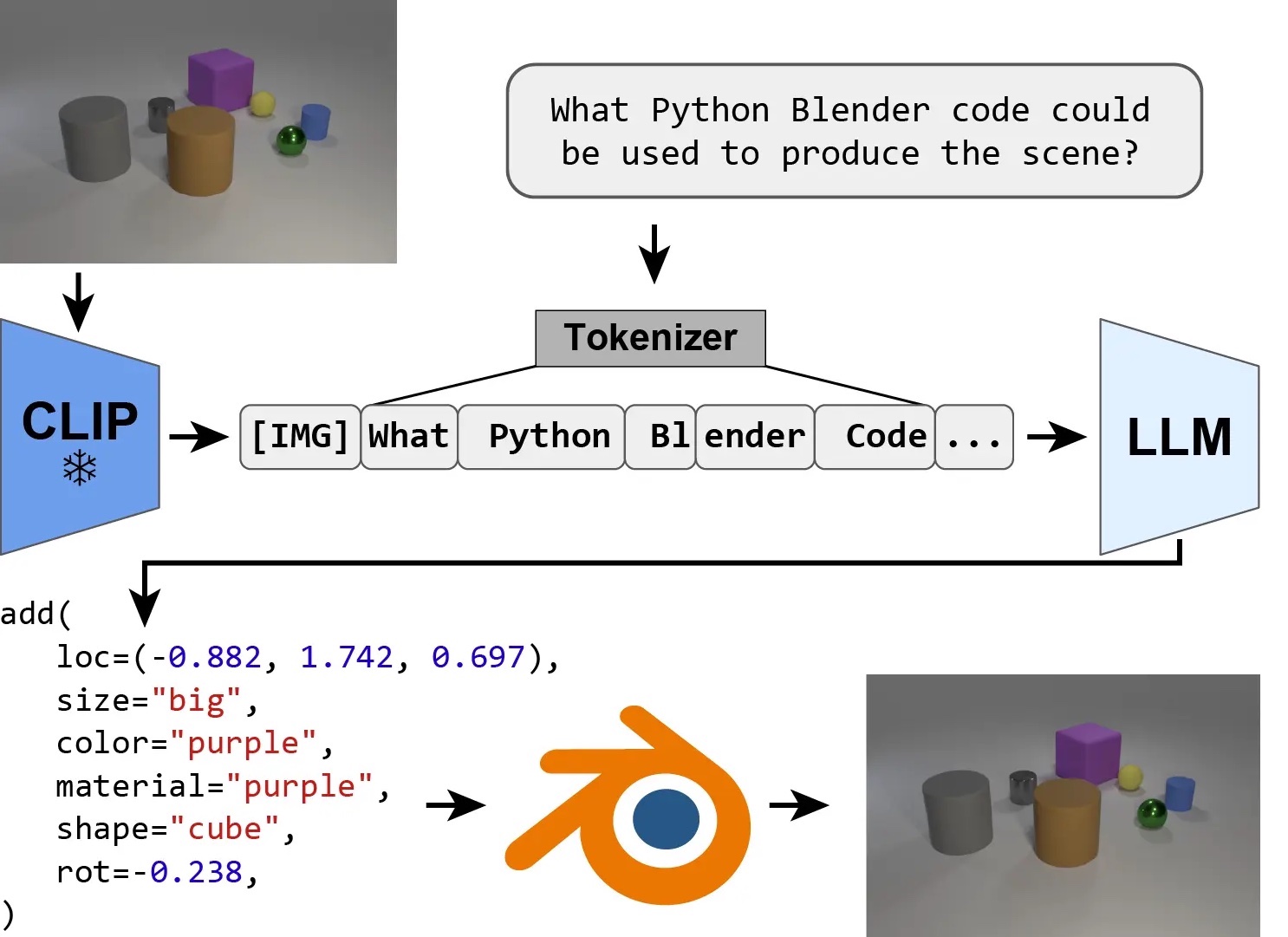
IG-LLM: Re-Thinking Inverse Graphics With Large Language Models
Peter Kulits*, Haiwen Feng*, Weiyang Liu, Victoria Abrevaya, Michael J. Black (*Co-first author) TMLR, 2024 - Selected to be presented at ICLR 2025 project page / arXiv We explored if inverse graphics could be approached as a code generation task and found it generalize surprisingly well to OOD cases! However, is it optimal for graphics? Our research identifies a fundamental limitation of LLMs for parameter estimation and offers a simple but effective solution. |
|
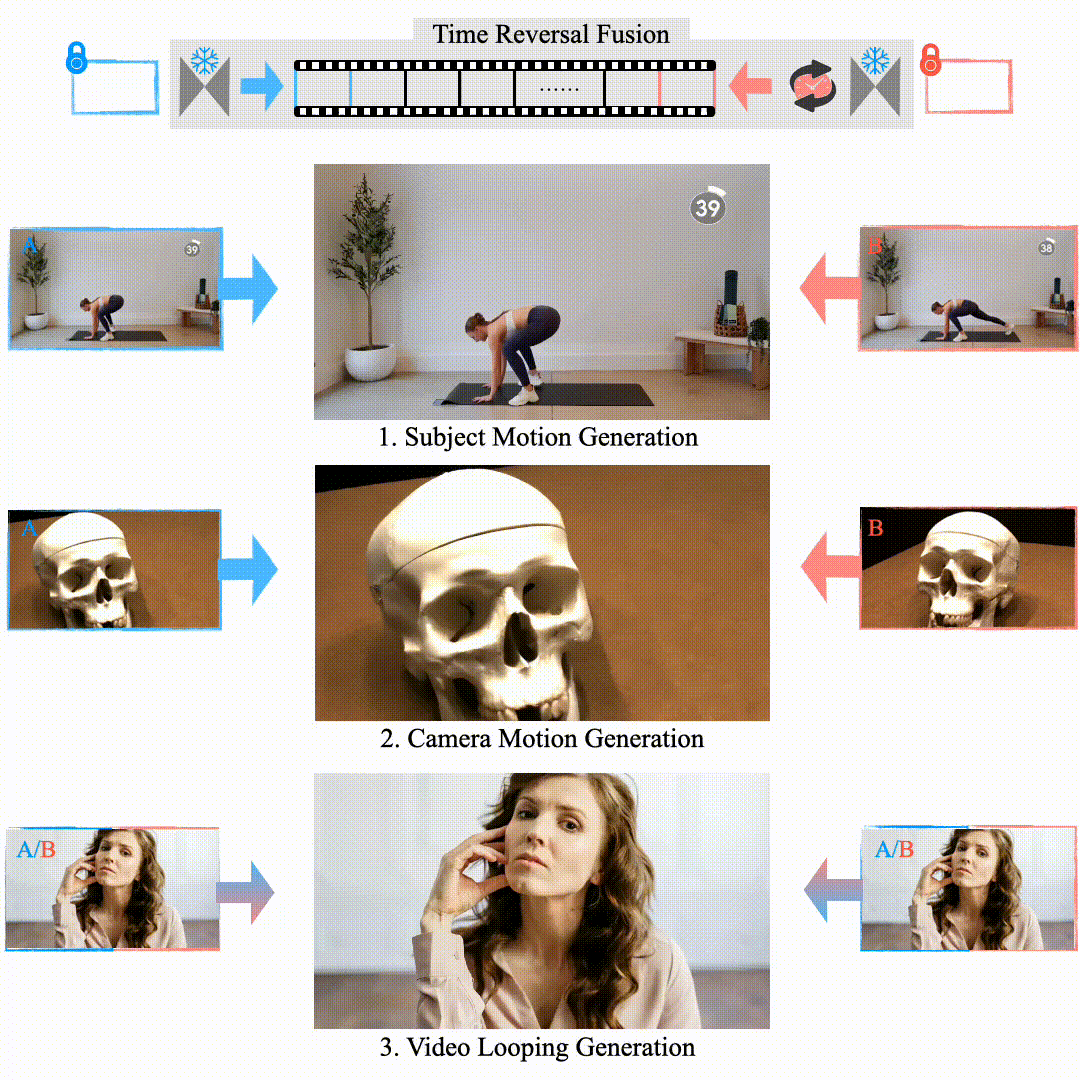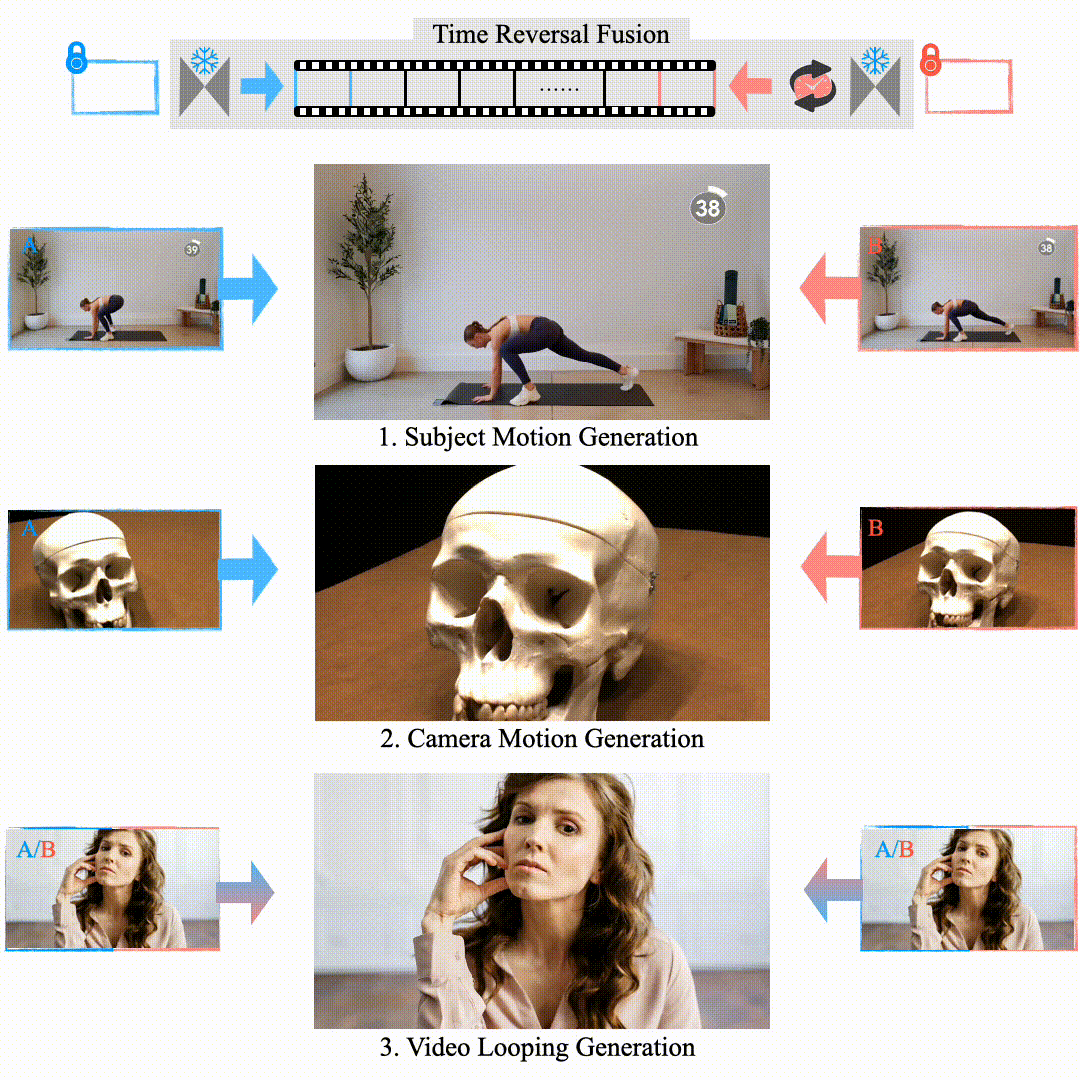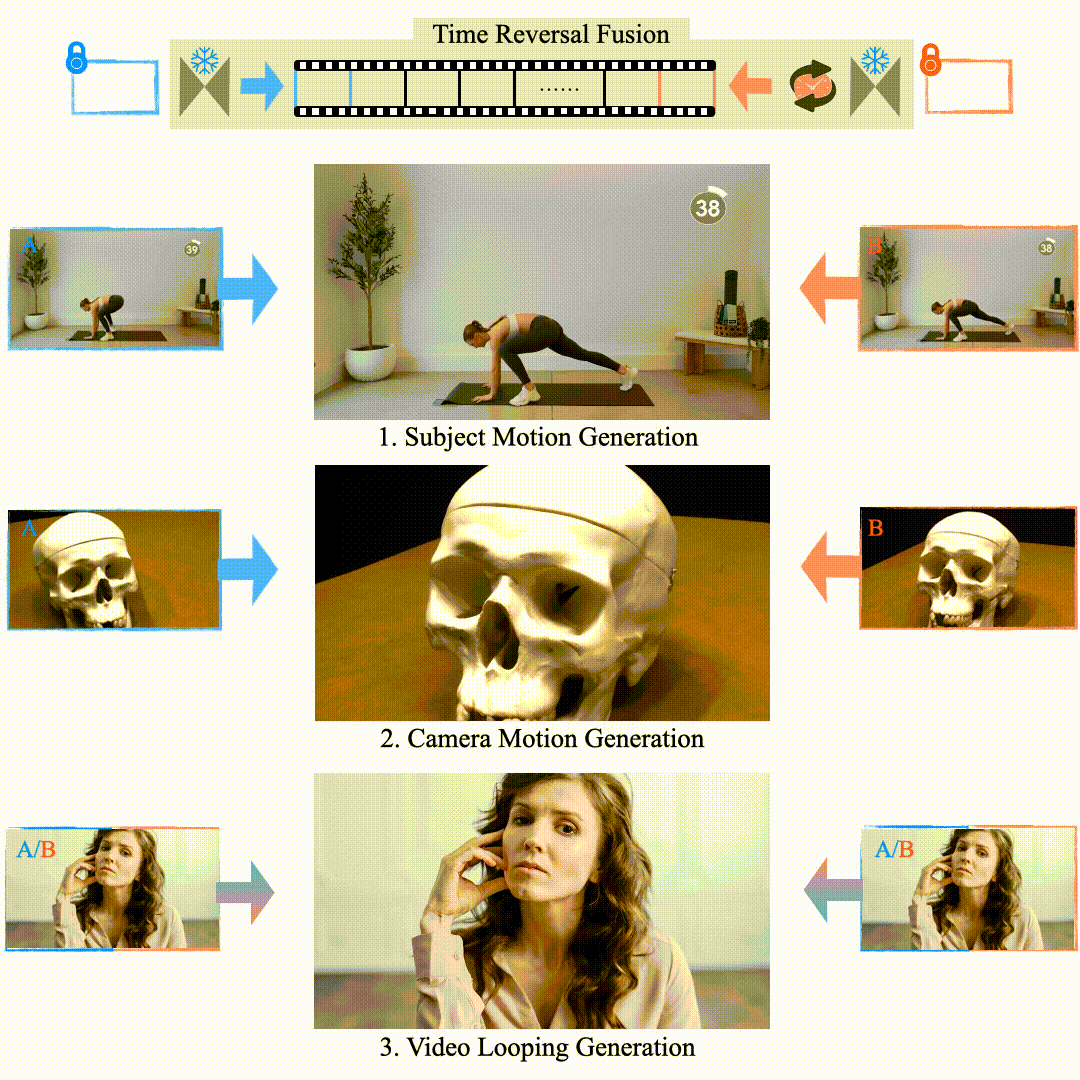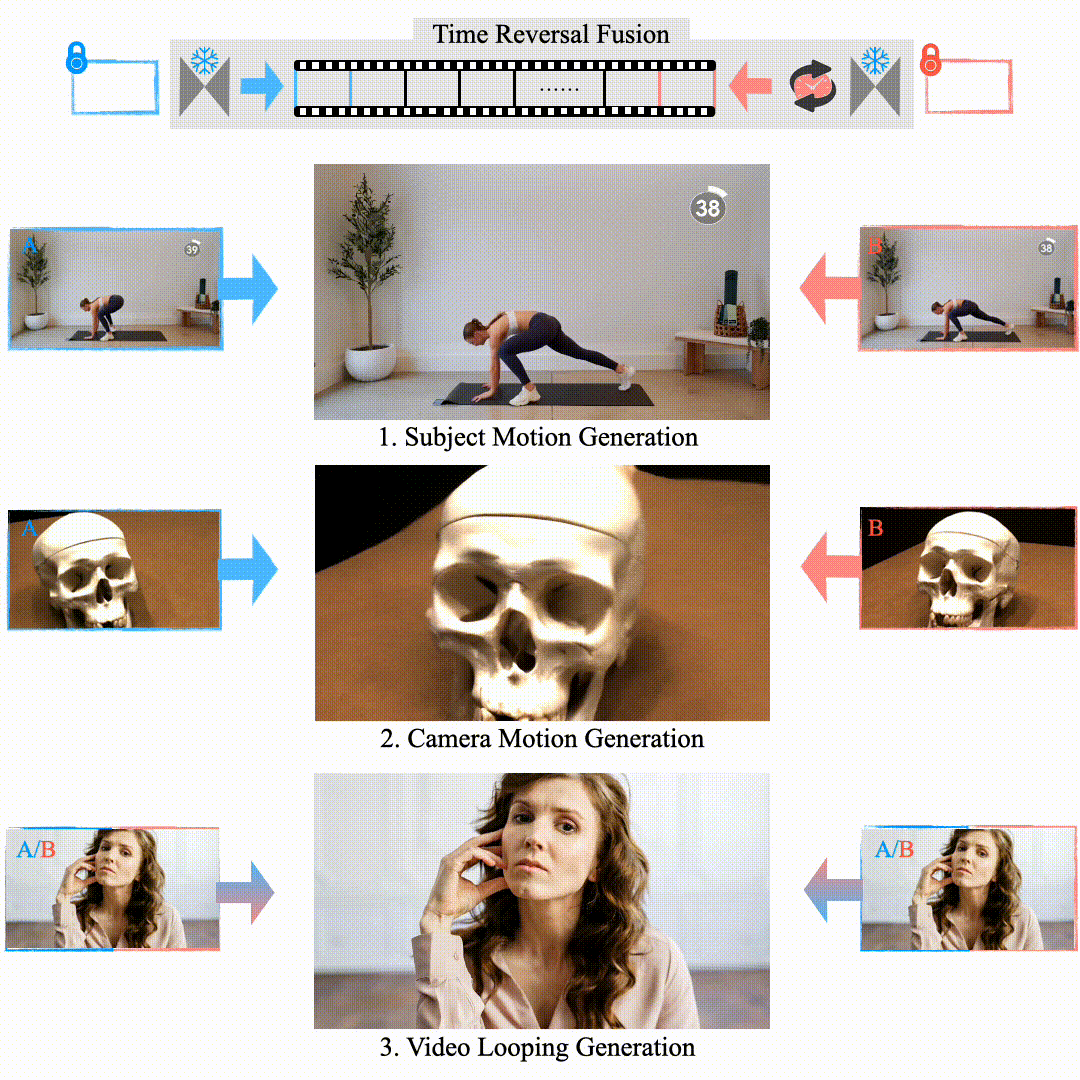
Explorative Inbetweening of Time and Space
Haiwen Feng, Zheng Ding, Zhihao Xia, Simon Niklaus, Victoria Abrevaya, Michael J. Black, Xuaner Zhang ECCV, 2024 project page / arXiv We proposed "Time-Reversal Fusion" to enable the image-to-video model to generate towards a given end frame without any tuning. It not only provides a unified solution for three visual tasks but also probes the dynamic generation capability of the video diffusion model. |

|
OFT: Controlling Text-to-Image Diffusion by Orthogonal Finetuning
Zeju Qiu*, Weiyang Liu*, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, Bernhard Schoelkopf NeurIPS, 2023 project page / arXiv / code We proposed a principled PEFT method by orthogonally fine-tuning the pretrained model, resulting in superior alignment and faster convergence for controllable synthesis. |
|
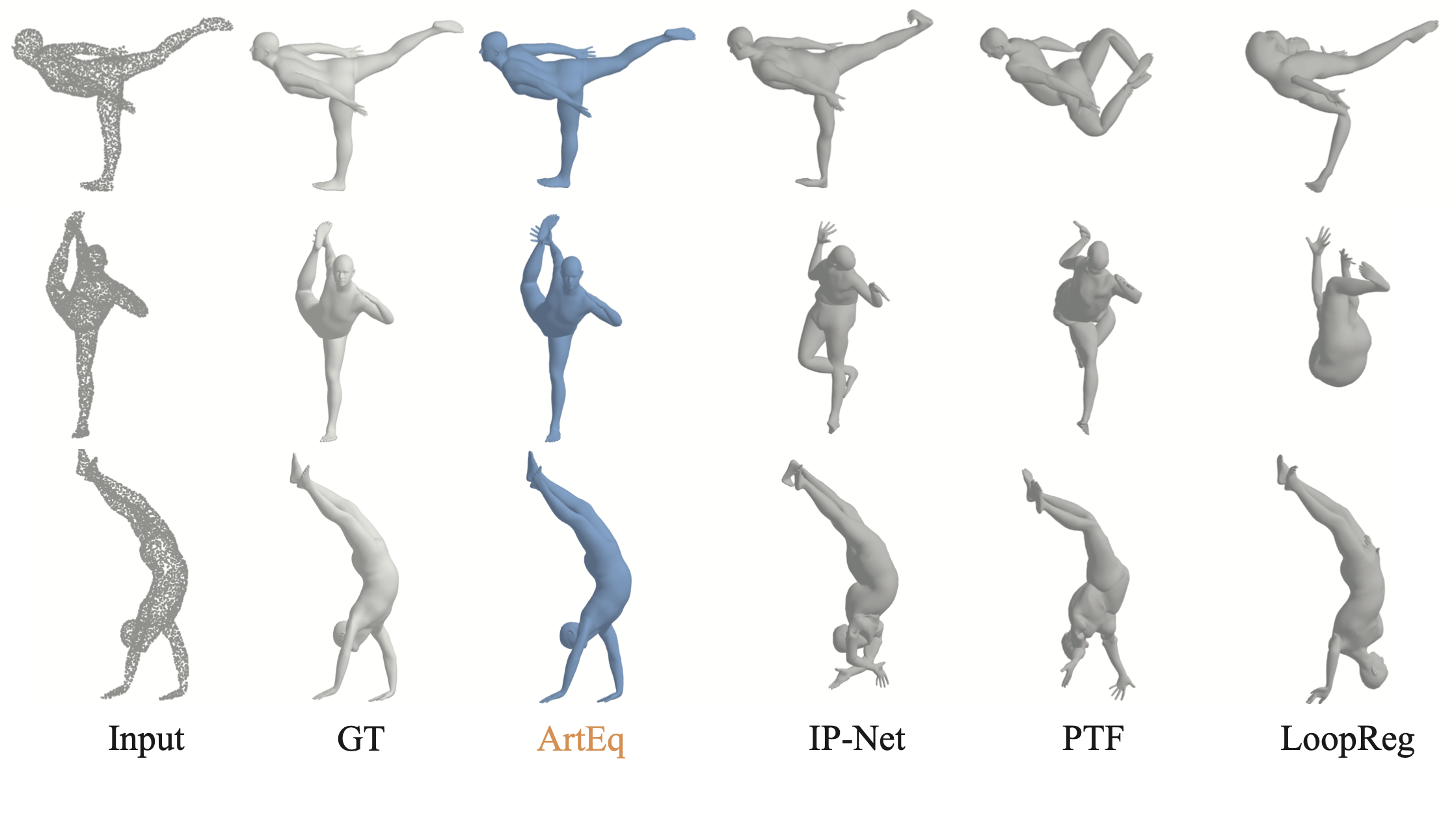
ArtEq: Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
Haiwen Feng, Peter Kulits, Shichen Liu, Michael J. Black, Victoria Abrevaya ICCV, 2023 (Oral Presentation) project page / arXiv / code We extended SE(3) Equivariance to articulated scenarios, achieving principled generalization for OOD body poses with 60% less error, and a network 1000 times faster and only 2.7% the size of the previous state-of-the-art model. |

|
TRUST: Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
Haiwen Feng, Timo Bolkart, Joachim Tesch, Michael J. Black, Victoria Abrevaya ECCV, 2022 project page / arXiv / code We conducted a systematic analysis of skin tone bias in 3D face albedo reconstruction and proposed the first unbiased albedo estimation evaluation suite (benchmark + metric). Additionally, we developed a principled method that reduces this bias by 80%. |

|
DECA: Learning an Animatable Detailed 3D Face Model from In-The-Wild Images
Yao Feng*, Haiwen Feng*, Michael J. Black, Timo Bolkart (*Equal contribution) SIGGRAPH, 2021 project page / arXiv / code We built the first animatable facial detail model that is purely learned from in-the-wild images and generalize to new expressions. |
|
The template is stole from Jon Barron. |