|
Haiwen (Haven) Feng
I'm a postdoctoral scholar at UC Berkeley, working with Angjoo Kanazawa and Trevor Darrell, building something new.
Before my PhD, I received both M.Sc. and B.Sc. degrees in Physics at the University of Tübingen, where I researched disentangled representation learning with Wieland Brendel and Matthias Bethge, and 3D morphable models with Timo Bolkart and Michael J. Black at MPI-IS. |

@Lake Wakatipu, New Zealand |
|
|
|
|
|
Research
My research focuses on building structural world models that are controllable by human and verifiable by design.
Selected publications are listed below. |

|
[schema]: Frontier Models with the Right Harness Achieve ~99% on ARC-AGI-3 Public
Guanning Zeng*, Jiani Wang, Wenjie Ma, Shaofeng Yin, Chenyang Wang, Shichen Liu, Angjoo Kanazawa, Wode Ni, Xiuyu Li*, Andrea Zanette*, Haiwen Feng* (*Project leads) Project release, 2026 project page / traces How can an agent solve a game without knowing any of its rules? Schema makes it think like a physicist: ground objects, relations, and goals; discover how they change; and encode both state and mechanism in an editable symbolic world model. It designs experiments, backtests hypotheses against history, and plans at zero action cost—reaching 99% RHAE with Opus 4.8 + Fable 5 and 95.35% with GPT-5.6 Sol on the ARC-AGI-3 public set. |

|
Playful Agentic Robot Learning
Junyi Zhang*†, Jiaxin Ge*†, Hanjun Yoo†, Letian Fu‡, Zihan Yang‡, Yaowei Liu‡, Raj Saravanan‡, Shaofeng Yin, Justin Yu, Dantong Niu, Zirui Wang, Roei Herzig, Ken Goldberg, Yutong Bai, David M. Chan, Ion Stoica, Angjoo Kanazawa, Jiahui Lei§, Haiwen Feng§, Trevor Darrell (*Project leads, ordered by coin flip; †, ‡, § Equal contribution) arXiv, 2026 project page / arXiv / code RATs lets embodied coding agents learn before downstream tasks arrive: they invent useful play goals, plan and execute robot programs, diagnose failures, and distill successful behaviors into a persistent code-skill library. The learned skills improve held-out manipulation and transfer across simulators and to real robots without fine-tuning the underlying model. |
|
Diffusion Policy Optimization without Drifting Apart
Haozhe Jiang, Haiwen Feng, Pieter Abbeel, Jiantao Jiao, Angjoo Kanazawa, Nika Haghtalab arXiv, 2026 project page / arXiv / code DiPOD diagnoses the double-drift failure mode in diffusion-model RL, where the variational bound separates from true likelihood and its proxy gradient becomes misaligned with the policy gradient. An on-policy ELBO regularizer interleaves self-distillation with policy improvement, stabilizing post-training across diffusion language models and continuous-control policies. |

|
Streaming Video Generation with Streaming Force Control
Hanhui Wang*, Yiming Xie*, Haiwen Feng, Zhaoyang Lv, Shenlong Wang†, Huaizu Jiang† (*Equal contribution, †Equal advising) SIGGRAPH Asia, 2026 project page / arXiv StreamForce is a causal, unified video generator that responds online to continuous local and global forces, even as their direction and magnitude change. Its distillation and autoregressive design reaches up to 16.6 FPS on a single GPU while improving force adherence and motion realism. |

|
Self-Improving 4D Perception via Self-Distillation
Nan Huang*, Pengcheng Yu*, Weijia Zeng, James M. Rehg, Angjoo Kanazawa, Haiwen Feng†, Qianqian Wang† (*Equal contribution, †Equal advising) arXiv, 2026 project page / arXiv Can 3D perception models improve without any 4D ground-truth? We show that self-distillation on unlabeled video, using the model's own predictions as targets, reliably bootstraps stronger 4D perception, scaling beyond the limits of supervised data and pointing toward a path for continually self-improving 4D geometric models. |

|
VIGA: Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Shaofeng Yin, Jiaxin Ge, Zora Zhiruo Wang, Xiuyu Li, Michael J. Black, Trevor Darrell, Angjoo Kanazawa, Haiwen Feng ECCV, 2026 project page / arXiv VIGA reframes inverse graphics as an agentic reasoning process: an MLLM iteratively writes, renders, compares, and revises graphics programs through a closed loop with evolving context memory, without any task-specific modules or fine-tuning. |

|
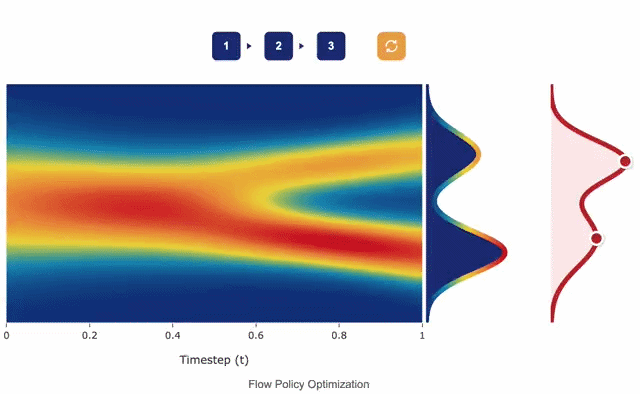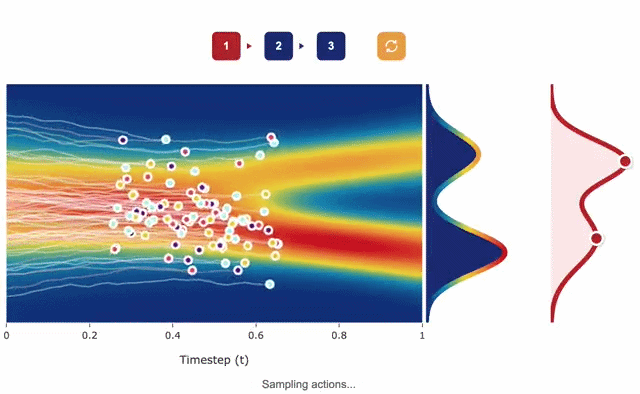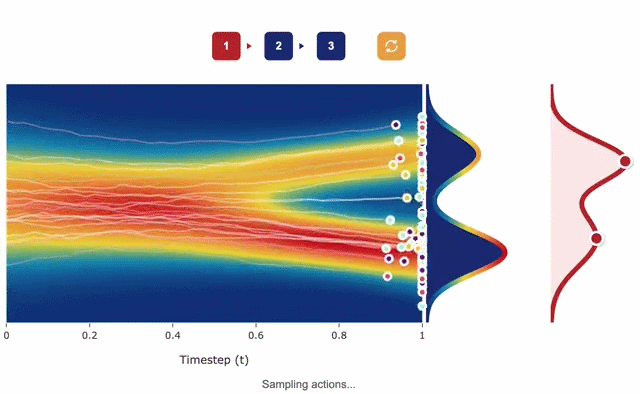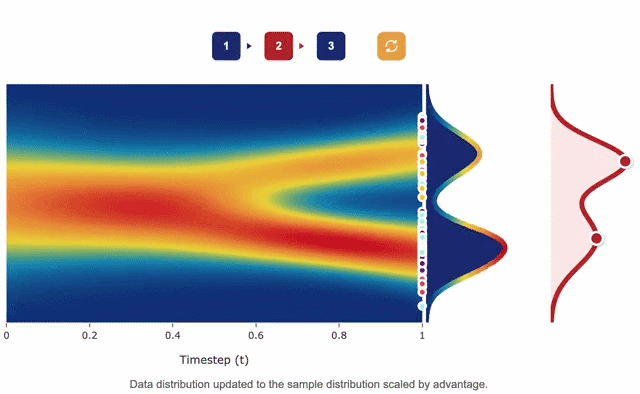
Maximum Likelihood Reinforcement Learning
Fahim Tajwar*, Guanning Zeng*, Yueer Zhou, Yuda Song, Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov, Haiwen Feng, Andrea Zanette (*Equal contribution) ICML, 2026 ICLR, 2026 SPOT Workshop (Best Paper) project page / arXiv Standard RL objectives drift away from maximum likelihood as compute grows. MaxRL closes this gap with a compute-indexed family of objectives that smoothly interpolates between REINFORCE and maximum likelihood, equipped with an unbiased policy-gradient estimator. It Pareto-dominates existing methods across every tested model and task, yielding up to 20x test-time scaling efficiency over GRPO. |
|
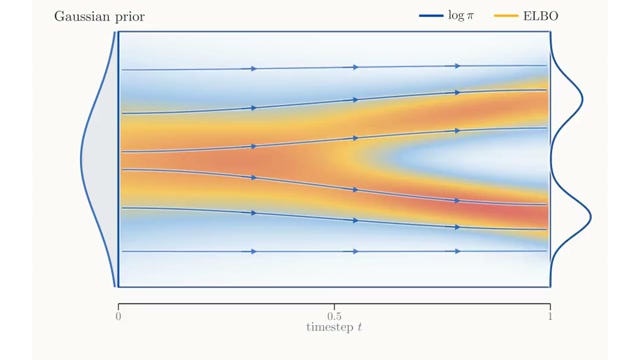
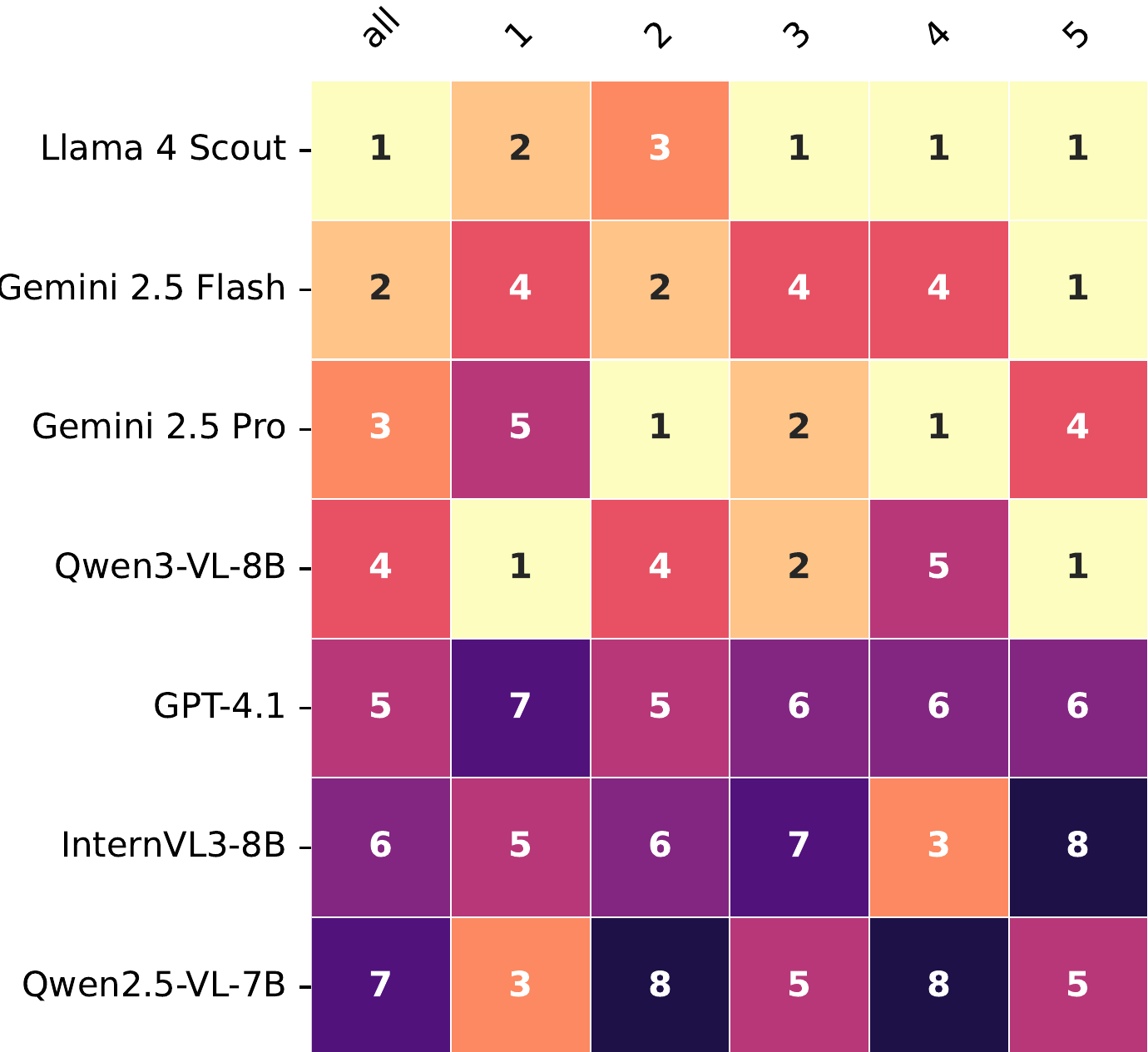
Flow Matching Policy Gradients
David McAllister*, Songwei Ge*, Brent Yi*, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, Angjoo Kanazawa (*Equal contribution) ICLR, 2026 project page / arXiv FPO brings flow matching into on-policy RL by casting policy optimization as maximizing an advantage-weighted ratio derived from the conditional flow matching loss, fully compatible with PPO-clip. Unlike prior diffusion-based RL methods, FPO is agnostic to the choice of integrator at training and inference time, and shows that flow-based policies learn multimodal action distributions that outperform Gaussian policies. |
|
Visually Prompted Benchmarks Are Surprisingly Fragile
Haiwen Feng*, Long Lian*, Lisa Dunlap*, Jiahao Shu, XuDong Wang, Renhao Wang, Trevor Darrell, Alane Suhr, Angjoo Kanazawa (*Equal contribution) arXiv, 2025 project page / arXiv / code Visually prompted VLM benchmarks are far more fragile than they look: seemingly irrelevant details — marker color, size, even JPEG compression — can completely flip model rankings on leaderboards. We introduce VPBench, a larger benchmark with 16 visual marker variants designed to expose this instability and enable robust evaluation. |

|
GenLit: Reformulating Single-Image Relighting as Video Generation
Shrisha Bharadwaj*, Haiwen Feng*, Giorgio Becherini, Victoria Fernandez Abrevaya, Michael J. Black (*Equal contribution, listed alphabetically) SIGGRAPH Asia, 2025 project page / arXiv Could we reformulate single image near-field relighting as a video generation task? By leveraging video diffusion models and a small synthetic dataset, we achieve realistic relighting effects with cast shadows on real images without explicit 3D. Our work reveals the potential of foundation models in understanding physical properties and performing graphics tasks. |
|
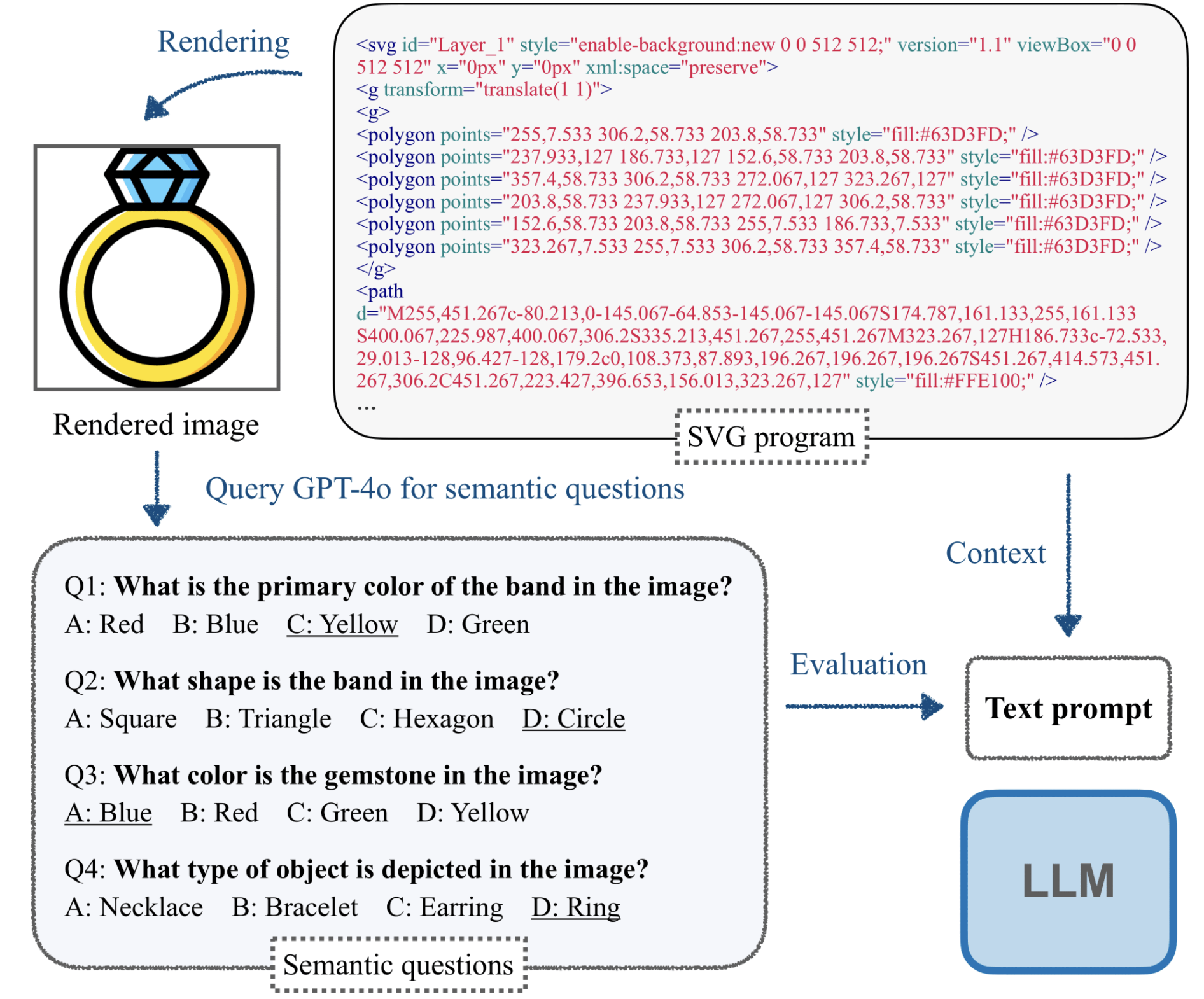
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Haiwen Feng*, Junyi Zhang*, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, Angjoo Kanazawa (*Equal contribution, listed alphabetically) ICCV, 2025 project page / arXiv What is the minimal representation required to model both geometry and correspondence of the 4D world? Could it be done in a unified framework? It turns out to be remarkably simple! We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate from monocular video, embedding the 4D understanding into the transformer-based backbone. |

|
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Boqian Li, Haiwen Fengᐩ, Zeyu Cai, Michael J. Black, Yuliang Xiu (ᐩProject lead) ICCV, 2025 (Highlight Presentation) project page / arXiv ArtEq was great, but how do we fit a body to a 3D clothed human point cloud? We propose ETCH, a novel pipeline leveraging local SE(3) equivariance to map cloth-to-body surfaces, encoding tightness as displacement vectors. ETCH simplifies fitting into a marker fitting task, outperforming state-of-the-art methods in accuracy and generalization across challenging scenarios. |

|
InterDyn: Controllable Interactive Dynamics with Video Diffusion Models
Rick Akkerman*, Haiwen Feng*ᐩ, Michael J. Black, Dimitrios Tzionas, Victoria Fernandez Abrevaya (*Equal contribution ᐩProject lead) CVPR, 2025 project page / arXiv Can we generate physical interactions without physics simulation? We leverage video foundation models as implicit physics simulators. Given an initial frame and a control signal of a driving object, InterDyn generates plausible, temporally consistent videos of complex object interactions. Our work demonstrates the potential of using video generative models to understand and predict real-world physical dynamics. |
|
SGP-Bench: Can Large Language Models Understand Symbolic Graphics Programs?
Zeju Qiu*, Weiyang Liu*, Haiwen Feng*, Zhen Liu, Tim Z. Xiao, Katherine M. Collins, Joshua B. Tenenbaum, Adrian Weller, Michael J. Black, Bernhard Schölkopf (*Joint first author) ICLR, 2025 (Spotlight Presentation) project page / arXiv / code We questioned whether LLMs can "imagine" how the corresponding graphics content would look without visually seeing it! This task requires both low-level skills (e.g., counting objects, identifying colors) and high-level reasoning (e.g., interpreting affordances, understanding semantics). Our benchmark effectively differentiates models by their reasoning abilities, with performance consistently aligning with the scaling law! |
|
IG-LLM: Re-Thinking Inverse Graphics With Large Language Models
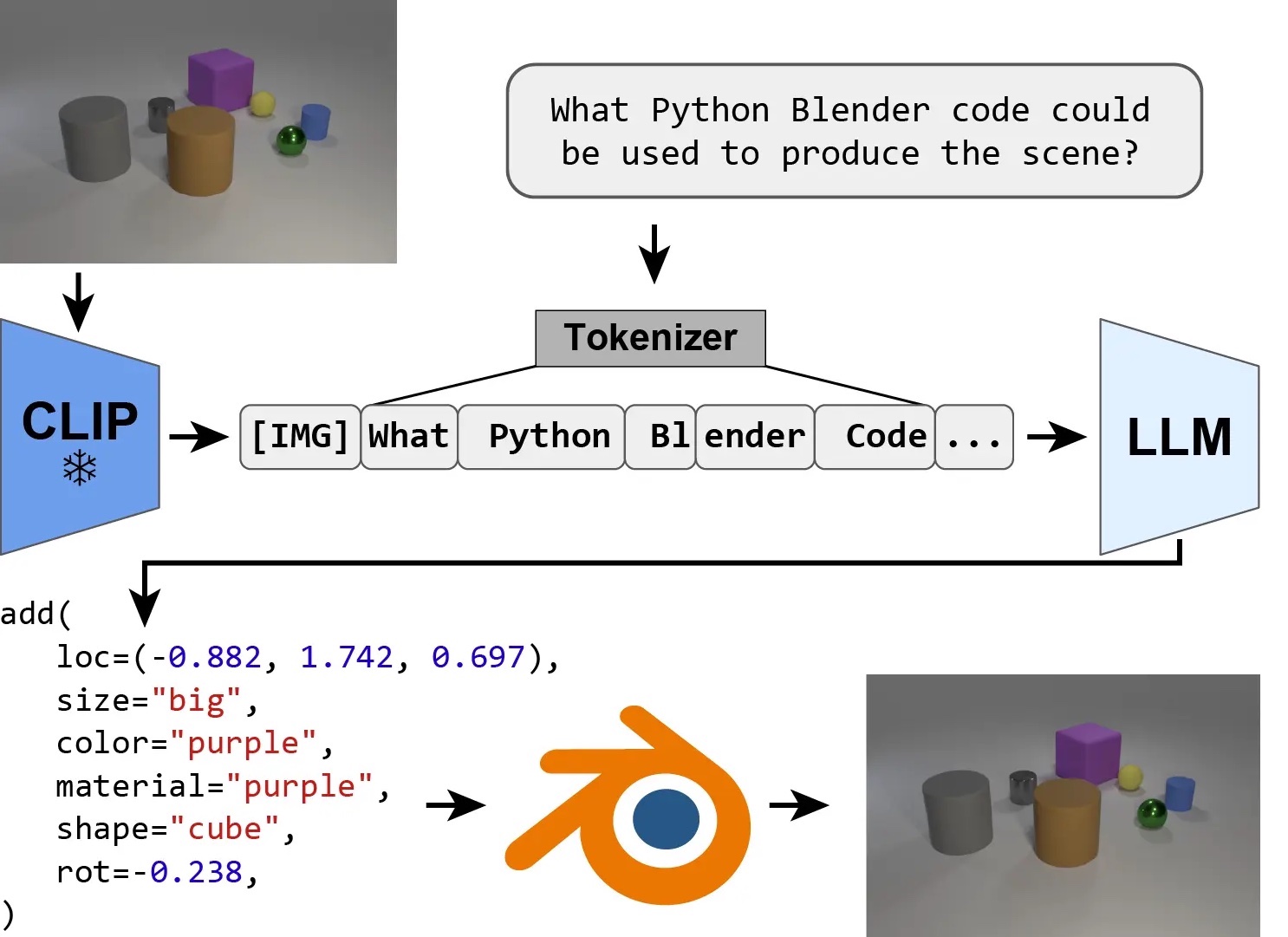
Peter Kulits*, Haiwen Feng*, Weiyang Liu, Victoria Abrevaya, Michael J. Black (*Co-first author) TMLR, 2024 - Selected to be presented at ICLR 2025 project page / arXiv We explored if inverse graphics could be approached as a code generation task and found it generalize surprisingly well to OOD cases! However, is it optimal for graphics? Our research identifies a fundamental limitation of LLMs for parameter estimation and offers a simple but effective solution. |
|
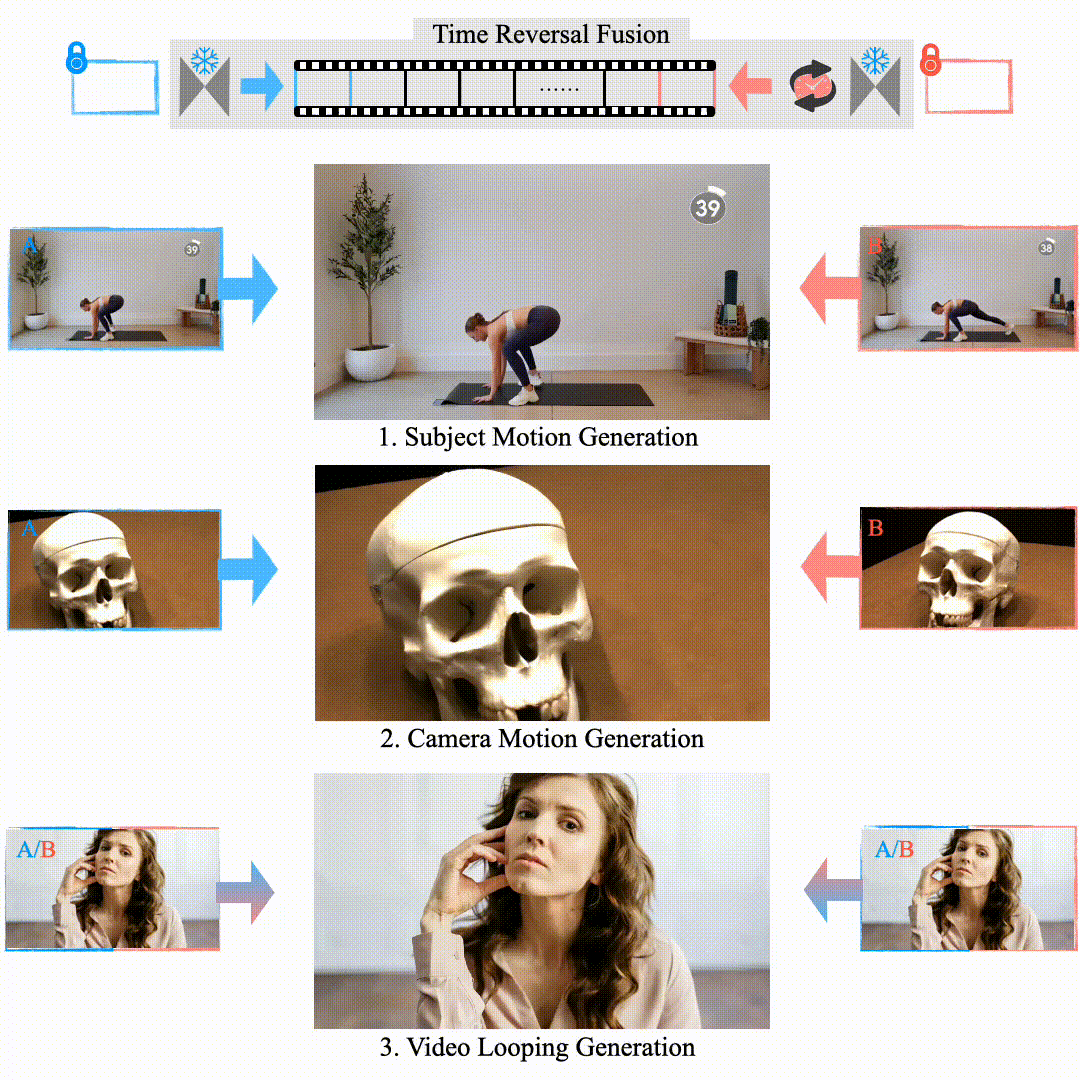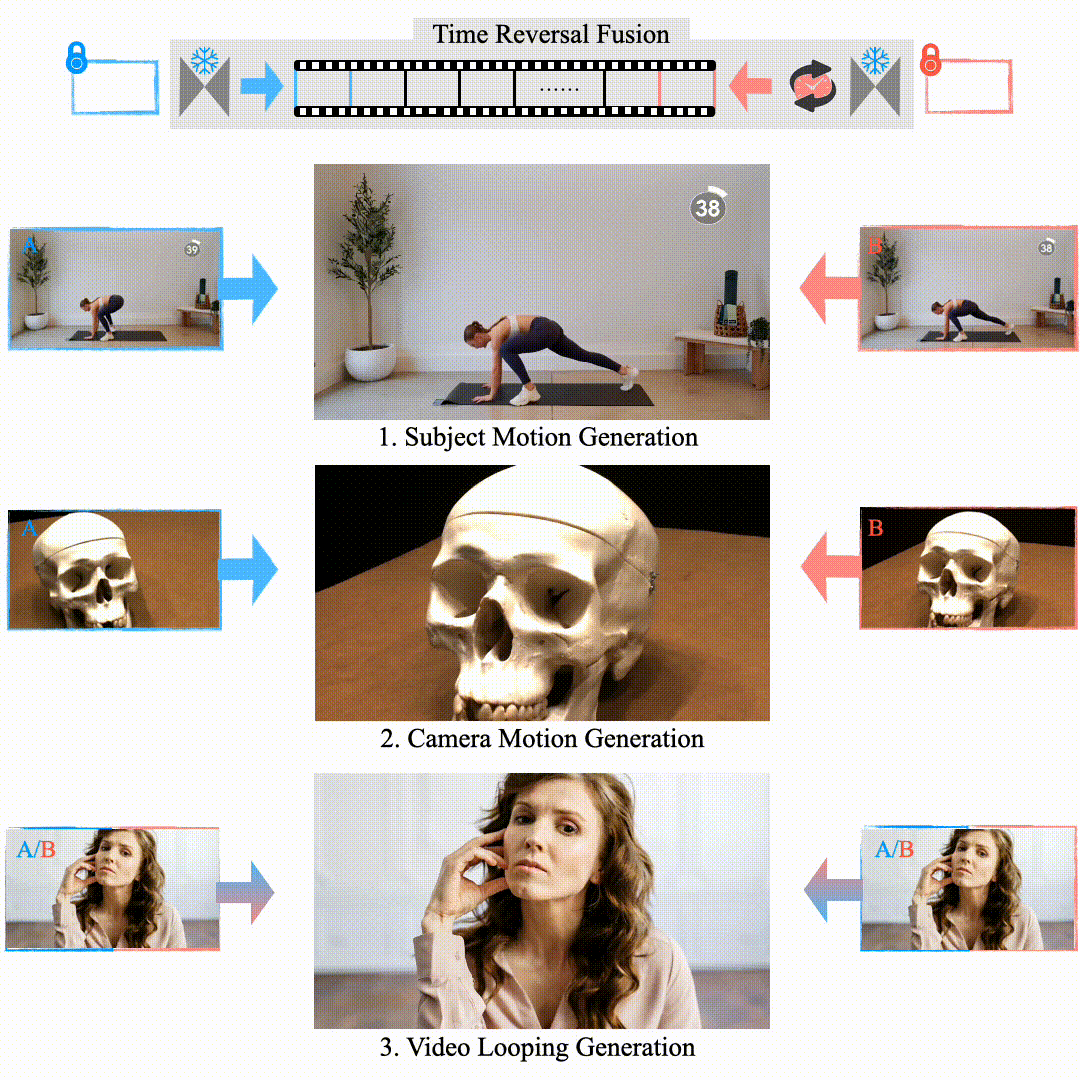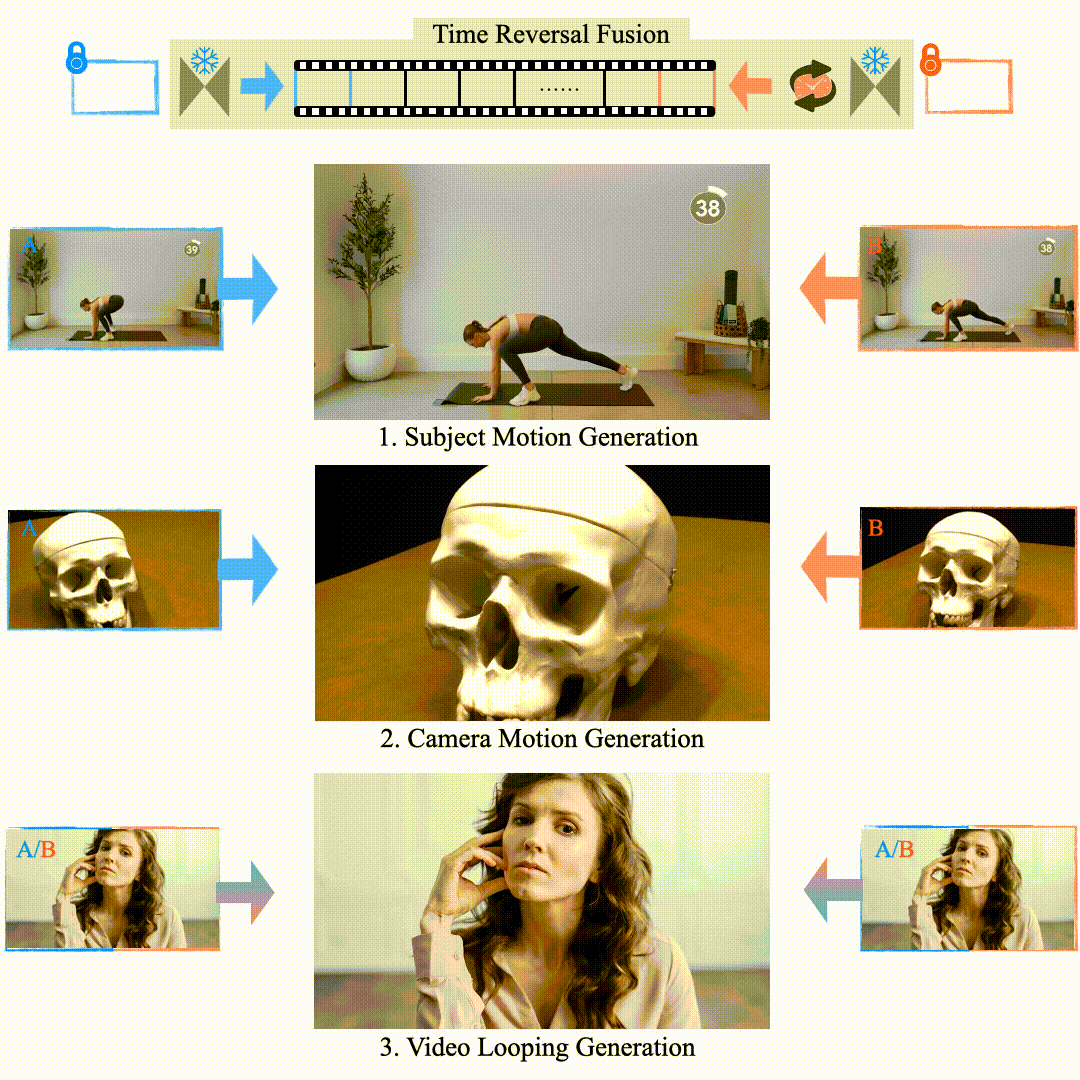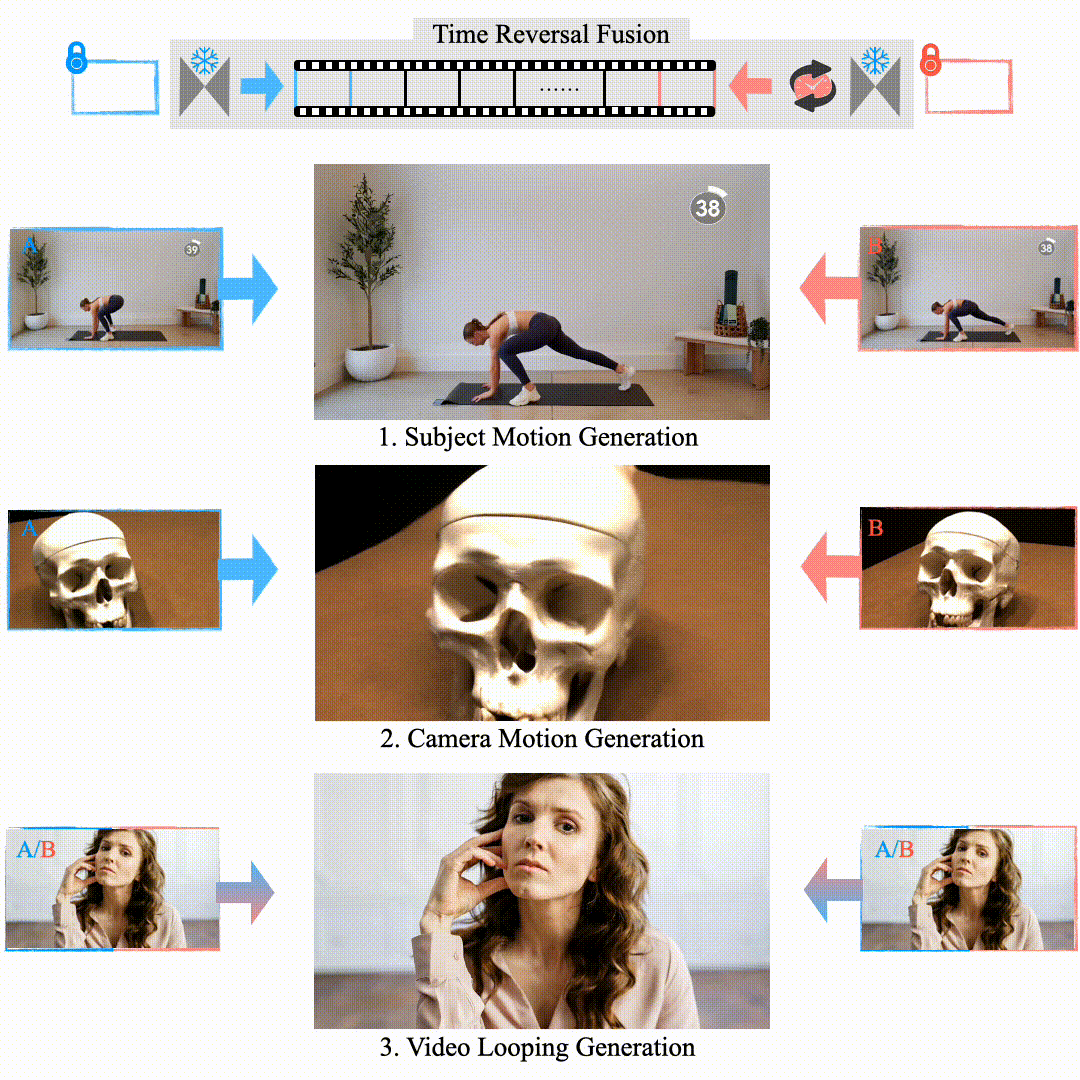
Explorative Inbetweening of Time and Space
Haiwen Feng, Zheng Ding, Zhihao Xia, Simon Niklaus, Victoria Abrevaya, Michael J. Black, Xuaner Zhang ECCV, 2024 project page / arXiv We proposed "Time-Reversal Fusion" to enable the image-to-video model to generate towards a given end frame without any tuning. It not only provides a unified solution for three visual tasks but also probes the dynamic generation capability of the video diffusion model. |

|
OFT: Controlling Text-to-Image Diffusion by Orthogonal Finetuning
Zeju Qiu*, Weiyang Liu*, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, Bernhard Schoelkopf NeurIPS, 2023 project page / arXiv / code We proposed a principled PEFT method by orthogonally fine-tuning the pretrained model, resulting in superior alignment and faster convergence for controllable synthesis. |
|
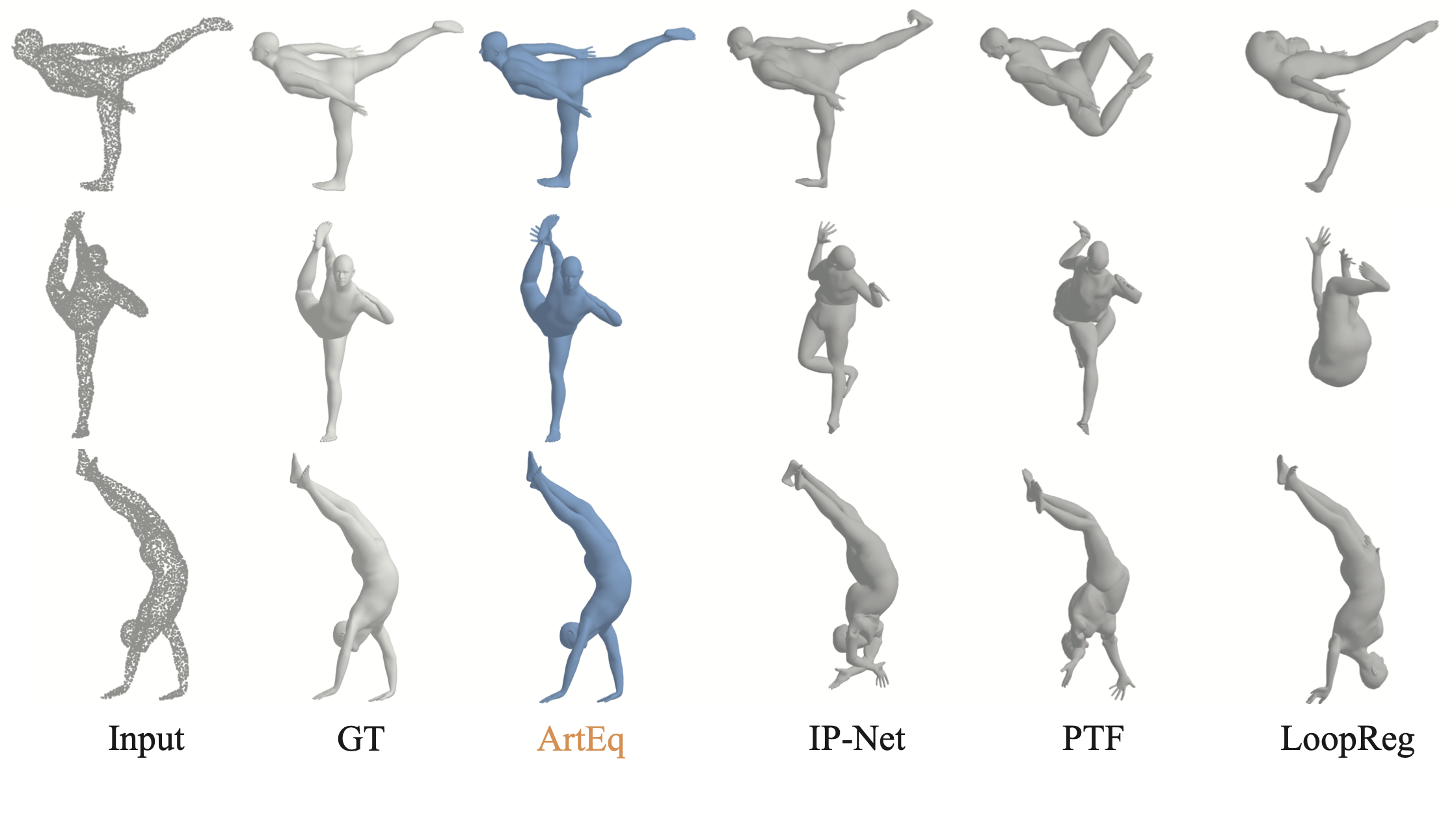
ArtEq: Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
Haiwen Feng, Peter Kulits, Shichen Liu, Michael J. Black, Victoria Abrevaya ICCV, 2023 (Oral Presentation) project page / arXiv / code We extended SE(3) Equivariance to articulated scenarios, achieving principled generalization for OOD body poses with 60% less error, and a network 1000 times faster and only 2.7% the size of the previous state-of-the-art model. |

|
TRUST: Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
Haiwen Feng, Timo Bolkart, Joachim Tesch, Michael J. Black, Victoria Abrevaya ECCV, 2022 project page / arXiv / code We conducted a systematic analysis of skin tone bias in 3D face albedo reconstruction and proposed the first unbiased albedo estimation evaluation suite (benchmark + metric). Additionally, we developed a principled method that reduces this bias by 80%. |

|
DECA: Learning an Animatable Detailed 3D Face Model from In-The-Wild Images
Yao Feng*, Haiwen Feng*, Michael J. Black, Timo Bolkart (*Equal contribution) SIGGRAPH, 2021 project page / arXiv / code We built the first animatable facial detail model that is purely learned from in-the-wild images and generalize to new expressions. |
|
The template is stole from Jon Barron. |